If you’re searching for practical guidance on DevOps deployment strategies, you’re likely looking to streamline releases, reduce downtime, and build a more reliable software delivery pipeline. With so many tools, frameworks, and methodologies available, it can be difficult to determine which deployment approach best fits your team’s workflow and business goals.
This article breaks down the most effective DevOps deployment strategies, including blue-green deployments, canary releases, rolling updates, and feature flags. You’ll learn how each strategy works, when to use it, and the trade-offs to consider so you can make informed, confident decisions.
Our insights are grounded in real-world implementation experience, industry best practices, and analysis of modern DevOps toolchains used by high-performing engineering teams. By the end, you’ll have a clear understanding of how to choose and implement a deployment strategy that improves speed, stability, and scalability in your development lifecycle.
From Code to Customer: Mastering Modern Deployment
Deployment is the bridge between a developer’s laptop and a user’s screen. It’s where value becomes visible. Yet, like swapping engines mid-flight, it carries risk.
In CI/CD—continuous integration and continuous delivery—deployment means releasing code into production, live environment customers touch. Some argue manual releases are safer. However, that’s like preferring paper maps over GPS; comforting, but slow.
Modern DevOps deployment strategies automate rollouts, using blue-green deployments—running two identical environments—to shift traffic smoothly. This reduces downtime and bugs. Pro tip: monitor metrics in time; data is air-traffic control. Ultimately, deployment turns code into value.
The Core Principles: What Makes a Deployment “Effective”?
Before choosing tactics, define the goal. An effective deployment delivers new code with minimal downtime, reduced risk, fast feedback, and painless rollbacks (because no one likes a 2 a.m. fire drill). In other words, it works—and if it doesn’t, it fails safely.
Start with a strong CI/CD foundation. Continuous Integration (CI) means merging code frequently to catch issues early. Continuous Delivery keeps code production-ready at all times. Continuous Deployment automatically releases every approved change. Together, they create a steady, low-drama release cycle—more “The Mandalorian” precision, less chaos.
Equally important is limiting the blast radius, or the scope of damage if something breaks. Use staged rollouts, feature flags, and automated tests to protect most users while validating changes.
Some argue heavy safeguards slow innovation. However, disciplined DevOps deployment strategies actually speed delivery by preventing costly failures. Pro tip: measure rollback time—it’s your real safety net.
A Deep Dive into Key Deployment Patterns

Modern software teams rely on DevOps deployment strategies to ship features faster without breaking what already works. But not all deployment patterns are created equal. Each has trade-offs, and choosing the wrong one can mean downtime, frustrated users, or late-night rollback drills (the kind fueled by cold pizza and regret).
Let’s break down four key patterns, define what they actually mean, and explore where they shine—and where critics raise valid concerns.
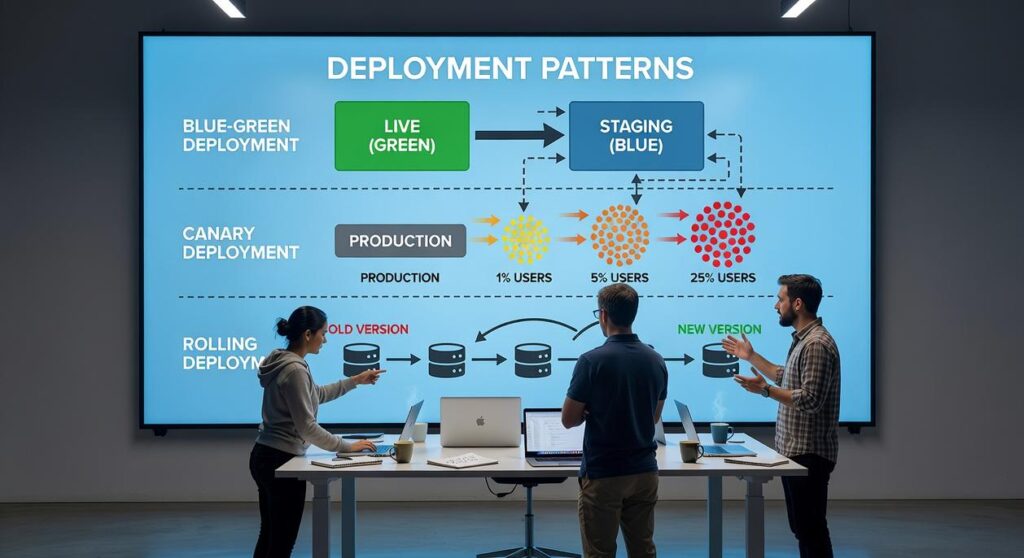
Blue-Green Deployment
Definition: Blue-Green deployment uses two identical production environments. Blue runs the current live version, while Green hosts the new release. Once Green is fully tested, traffic switches over instantly.
Benefits:
- Near-zero downtime during releases
- Instant rollback by redirecting traffic to Blue
- Reduced deployment risk
For example, large e-commerce platforms often use Blue-Green during peak shopping seasons. If checkout fails after a release, traffic can revert immediately—protecting revenue and reputation.
Counterargument: Critics point out the cost. Maintaining duplicate infrastructure can double hosting expenses. For startups operating on tight margins, that’s significant.
That’s fair. However, the cost of downtime can exceed infrastructure savings. According to Gartner, the average cost of IT downtime is $5,600 per minute (Gartner). For revenue-generating platforms, Blue-Green often pays for itself.
Canary Deployment
Definition: A canary deployment releases new code to a small subset of users before rolling it out widely. The “canaries” act as early indicators of problems.
Benefits:
- Real-world validation with limited exposure
- Data-driven rollout decisions
- Lower blast radius if issues arise
Streaming platforms frequently use canary releases to test new recommendation algorithms on 5% of users before expanding.
Counterargument: Rollouts take longer and require strong observability tools. Without robust monitoring, subtle issues may go unnoticed.
True—but modern monitoring platforms like Datadog and Prometheus make granular tracking feasible. Pro tip: define success metrics before launching the canary. Otherwise, you’re measuring vibes instead of data.
Rolling Deployment
Definition: Rolling deployment gradually replaces old instances with new ones, either one at a time or in batches. Both versions temporarily coexist.
Benefits:
- No need for duplicate environments
- Efficient use of infrastructure
- Straightforward implementation in containerized systems like Kubernetes
Many SaaS platforms prefer rolling updates because they align naturally with auto-scaling clusters.
Counterargument: If the old and new versions aren’t backward compatible—especially at the database level—users may experience instability.
That’s a legitimate concern. Schema versioning and backward-compatible APIs are essential safeguards. Without them, rolling updates can feel like changing airplane parts mid-flight.
A/B Testing (via Feature Flags)
Definition: Feature flags allow teams to deploy code in a dormant state and activate it selectively for user segments. This separates deployment (technical release) from feature exposure (business release).
Benefits:
- Precise control over user experience
- Business metric experimentation
- Instant feature rollback without redeploying
Companies like Netflix and Amazon rely heavily on feature flags to test UI changes and pricing experiments.
Counterargument: Feature flags increase code complexity and technical debt if not managed carefully.
Agreed. Poorly maintained flags can clutter codebases. A centralized flag management system is essential.
Interestingly, feature flag experimentation often complements insights from the role of ai in software engineering workflows, where AI-driven analytics help teams interpret A/B results faster.
In the end, no single pattern wins universally. The best choice depends on risk tolerance, infrastructure budget, observability maturity, and business goals. Deployment isn’t just about pushing code—it’s about protecting users while enabling innovation.
Automating Your Deployments: Essential Tools and Practices
Automating deployments isn’t just a technical upgrade—it’s a competitive advantage. When you remove manual steps, you reduce human error (the kind that causes 2 a.m. rollbacks) and gain faster, more predictable releases. That means quicker feature delivery, happier users, and less firefighting for your team.
First, CI/CD platforms like GitLab CI, GitHub Actions, and Jenkins orchestrate your build, test, and deploy pipeline. In other words, every code change is automatically validated before reaching production—saving you time and protecting your reputation.
Next, Infrastructure as Code (IaC) tools such as Terraform or Ansible ensure environments are identical and reproducible. This consistency makes DevOps deployment strategies like Blue-Green or rolling updates far less risky.
Meanwhile, containerization and orchestration with Docker and Kubernetes keep applications portable and scalable.
Finally, monitoring and observability tools like Prometheus or Datadog provide real-time insights, so you can catch issues early and deploy with confidence—not crossed fingers.
Building a Resilient and Agile Delivery Pipeline
Ultimately, there is no single “best” deployment strategy. Instead, the right choice depends on your application’s architecture, your team’s risk tolerance, and your users’ expectations. What matters most is moving away from manual, high-stakes “big bang” releases that slow innovation and amplify risk. By adopting automated DevOps deployment strategies like Canary or Blue-Green, you reduce downtime, catch issues early, and ship features with confidence. In other words, you gain speed without sacrificing stability (yes, you can have both). Start small: automate one manual step or add a health check, and build resilience from there.
Take Control of Your DevOps Deployment Strategy Today
You came here looking for clarity on how to implement smarter, faster, and more reliable DevOps deployment strategies—and now you have a practical roadmap to make that happen. From automation and CI/CD pipelines to monitoring, rollback planning, and team collaboration, you’ve seen what it takes to reduce downtime, eliminate bottlenecks, and ship with confidence.
The real challenge isn’t understanding DevOps. It’s struggling with slow releases, inconsistent environments, and deployment failures that cost time, money, and trust. Those pain points don’t fix themselves.
The next step is simple: audit your current pipeline, identify one weak point, and implement a measurable improvement this week. Then build from there.
If you want proven insights, step-by-step guides, and expert-backed breakdowns trusted by thousands of tech professionals, explore our in-depth DevOps resources and start optimizing today. Your deployments should feel predictable—not painful. Take action now and turn your deployment process into a competitive advantage.
 There is a specific skill involved in explaining something clearly — one that is completely separate from actually knowing the subject. Zayric Vornhaven has both. They has spent years working with software development insights in a hands-on capacity, and an equal amount of time figuring out how to translate that experience into writing that people with different backgrounds can actually absorb and use.
Zayric tends to approach complex subjects — Software Development Insights, Tech Tutorials and How-To Guides, Emerging Tech Trends being good examples — by starting with what the reader already knows, then building outward from there rather than dropping them in the deep end. It sounds like a small thing. In practice it makes a significant difference in whether someone finishes the article or abandons it halfway through. They is also good at knowing when to stop — a surprisingly underrated skill. Some writers bury useful information under so many caveats and qualifications that the point disappears. Zayric knows where the point is and gets there without too many detours.
The practical effect of all this is that people who read Zayric's work tend to come away actually capable of doing something with it. Not just vaguely informed — actually capable. For a writer working in software development insights, that is probably the best possible outcome, and it's the standard Zayric holds they's own work to.
There is a specific skill involved in explaining something clearly — one that is completely separate from actually knowing the subject. Zayric Vornhaven has both. They has spent years working with software development insights in a hands-on capacity, and an equal amount of time figuring out how to translate that experience into writing that people with different backgrounds can actually absorb and use.
Zayric tends to approach complex subjects — Software Development Insights, Tech Tutorials and How-To Guides, Emerging Tech Trends being good examples — by starting with what the reader already knows, then building outward from there rather than dropping them in the deep end. It sounds like a small thing. In practice it makes a significant difference in whether someone finishes the article or abandons it halfway through. They is also good at knowing when to stop — a surprisingly underrated skill. Some writers bury useful information under so many caveats and qualifications that the point disappears. Zayric knows where the point is and gets there without too many detours.
The practical effect of all this is that people who read Zayric's work tend to come away actually capable of doing something with it. Not just vaguely informed — actually capable. For a writer working in software development insights, that is probably the best possible outcome, and it's the standard Zayric holds they's own work to.
